Research methods are the structured procedures researchers use to ask questions, collect evidence, analyse it, and report what they found in a way that other researchers can scrutinise and build on. The methods you choose, and how rigorously you apply them, determine whether your findings can support clinical decisions, policy changes, or further investigation. Sloppy methods produce results that even the researcher should not trust.
This guide walks the research lifecycle in order: framing the question and choosing a design, planning the sample, securing ethics approval, selecting the right statistical tests, managing the data and protecting participant privacy, writing for reproducibility, reporting against the appropriate standard, appraising the result, and avoiding the methodological pitfalls that catch new and experienced researchers alike. Every step has documented best practice. The discipline is in following it.
Key takeaways
- The research lifecycle moves from question to design to ethics to data to analysis to reporting; each step has documented standards.
- Match the study design to the question: RCT for causal claims about interventions, cohort for prospective association, case-control for rare outcomes, qualitative for meaning and process.
- Pre-specify sample size and statistical analysis before data collection; post-hoc decisions invite p-hacking and HARKing.
- Ethics approval is non-negotiable for human-participant research; literature reviews are usually exempt but always check your institution's policy.
- Choose the statistical test from the data's properties (type, distribution, sample size), not from familiarity. Tooling can surface candidate tests but does not replace statistical reasoning.
- Report against the standard that fits the design: CONSORT for RCTs, STROBE for observational studies, COREQ for qualitative, TRIPOD for prediction models, PRISMA 2020 for systematic reviews.
- Pre-register the protocol, share the data and code where possible, and provide a complete audit trail of analytical decisions.
What are research methods?
Research methods are the structured procedures used to investigate a question and produce evidence that can be appraised, replicated, and built on. They span the full lifecycle: framing the question, choosing a design, planning the sample, securing ethics approval, collecting and managing the data, analysing it, and reporting against an appropriate standard.
Two dimensions distinguish broad approaches. Quantitative methods use measurement and statistical inference to estimate effects, associations, or population parameters. Qualitative methods use interviews, observation, and document analysis to surface meaning, process, and context. Mixed-methods designs combine the two, typically when the question has both a measurable component and a contextual one that quantification alone misses.
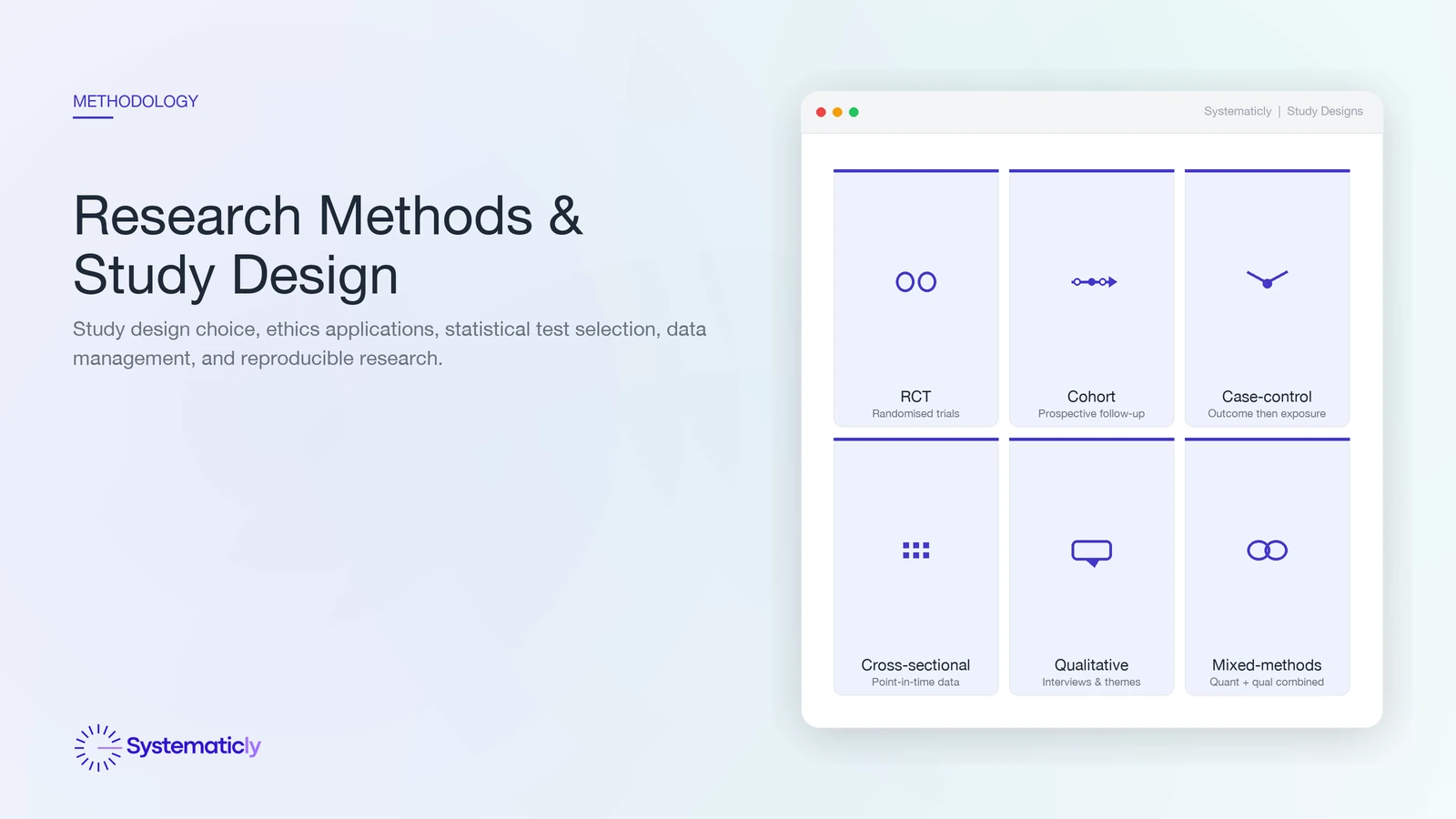
Choosing a study design
The study design is the strategy for answering the research question. The choice is constrained by what kind of claim you want to make, what is feasible to collect, and what is ethically permissible.
- Randomised controlled trial (RCT). The reference standard for causal claims about interventions. Random allocation balances measured and unmeasured confounders in expectation. Reported per CONSORT.
- Cohort study. Follows defined groups forward in time, comparing exposed and unexposed. Stronger for incidence and temporal sequence than for rare outcomes. Reported per STROBE.
- Case-control study. Compares cases with controls retrospectively. Efficient for rare outcomes but vulnerable to recall and selection bias. Reported per STROBE.
- Cross-sectional study. A snapshot of a population at one time point. Good for prevalence; cannot establish temporality. Reported per STROBE.
- Qualitative study. Interviews, focus groups, or ethnography. Answers questions about meaning, process, and lived experience that quantification cannot. Reported per COREQ.
- Mixed methods. Combines quantitative and qualitative approaches; used when neither alone answers the question.
- Systematic review. A structured synthesis of existing primary studies. The right tool when the question has been studied and the disagreement is in the synthesis, not the primary evidence. Reported per PRISMA 2020.
Sampling and statistical power
The sample is the bridge between the study and the population. Probability sampling (simple random, stratified, cluster) supports inference to the population; non- probability sampling (convenience, purposive, snowball) does not, but is sometimes the only feasible option for hard-to-reach populations or qualitative work.
Sample-size calculation pre-specifies how many participants are needed to detect a clinically meaningful effect with adequate statistical power, typically 0.80, at a chosen significance level, typically 0.05. Cohen's foundational text[1] is the standard reference, with tools such as G*Power and the R `pwr` package implementing the calculations. Underpowered studies routinely fail to detect real effects and contribute to the broader replication crisis.
Feasibility analysis at protocol stage looks beyond statistical power to the broader question of whether the study can realistically be done: is there enough relevant literature to inform the design, is the timeline plausible with the available team, and are the resources and skills required within reach. Honest feasibility work at the front end saves months of wasted effort at the back end.
Ethics applications and IRBs
Research involving human participants, their identifiable data, or their biological samples requires ethics approval before data collection begins. The standard is set by the Declaration of Helsinki[2] and operationalised through institutional review boards (IRBs in the US), human research ethics committees (HRECs in Australia and the UK), and equivalent bodies elsewhere. ICH-GCP[3] is the international standard for clinical trials.
- Informed consent. Participants must understand what is being asked, what the risks are, and that they can withdraw without penalty. Special protections apply to children, prisoners, and other groups with constrained autonomy.
- Risk minimisation. The application must show that risks are minimised and reasonable in relation to anticipated benefits.
- Data management plan. A description of how data will be collected, stored, accessed, retained, and ultimately destroyed or shared.
- Privacy protections. Compliance with the relevant framework: GDPR (EU), HIPAA (US health), the Australian Privacy Principles (APPs) locally, or the equivalent.
Systematic reviews of already-published literature are usually exempt from full ethics review, but always confirm with your institution. Individual-participant- data meta-analyses (IPD) typically require additional approvals because they involve participant-level data that may be re-identifiable.
Statistical test selection
The right statistical test follows from the data, not the other way around. The selection process is a small decision tree: what type of data (continuous, ordinal, categorical, time-to-event), how is it distributed (normal, skewed, count), how large is the sample, and what comparison are you making (between groups, within participants, association between variables, prediction).
Plain-English test selection helps you find the test you already know you need. It does not replace the statistical reasoning behind the choice. The infographic above is illustrative: the input is a question, the output is a candidate test family, and a competent researcher still needs to verify that the assumptions hold and the result is interpretable.
- Parametric tests (t-test, ANOVA, linear regression, Pearson correlation) assume continuous, approximately normally-distributed data and are more powerful when their assumptions hold.
- Non-parametric alternatives (Mann-Whitney, Kruskal-Wallis, Spearman correlation) handle ordinal data, small samples, and skewed distributions without distributional assumptions.
- Generalised linear models extend regression to non-normal outcomes (logistic for binary, Poisson for counts, Cox for time-to-event).
- Multilevel and mixed models handle hierarchically clustered data (patients within clinics, students within schools).
- Bayesian alternatives for any of the above, when prior information is informative or when posterior probability is more interpretable than a p-value.
Data management and privacy
Responsible data management is the operational backbone of reproducible research. It starts with the protocol's data-management plan and runs through collection, storage, access control, sharing, and ultimate retention or destruction. The practices that look like overhead at the start of a project look like obvious prudence by the time of submission, peer review, or audit.
- Pre-registration of the protocol on a public registry (OSF, AsPredicted, PROSPERO for systematic reviews) before data collection or analysis.
- Version-controlled instruments and code. Track every change to data-collection forms, extraction templates, and analytical scripts.
- Secure storage with appropriate access controls, separation of identifiable from de-identified data, and documented retention schedules.
- Audit trails for every analytical decision, AI-assisted or otherwise. Reproducibility means another team can re-run your analysis and get the same answer.
- Privacy compliance. GDPR (EU), HIPAA (US health), the Australian Privacy Principles (APPs). Where multiple frameworks apply, the strictest one in practice sets the floor.
- Zero-data-retention guarantees from any AI or cloud platform you use, with contractual assurance that user data is not retained or used to train models.
Reproducibility and open science
A study is reproducible when an independent researcher, given the same data and code, can arrive at the same result. It is replicable when an independent study, following the same methods on a new sample, finds a consistent effect. The replication crisis across psychology, biomedicine, and economics in the last decade has shifted these from aspirations to expectations.
- Pre-registration distinguishes confirmatory analyses (specified before seeing the data) from exploratory ones (post-hoc, hypothesis-generating).
- Registered reports go further: the protocol is peer-reviewed and provisionally accepted before the study runs, with publication contingent on adherence rather than on the result direction.
- Open data. Share de-identified data on a permanent repository (Zenodo, OSF, Dryad) with a DOI and a clear licence (CC-BY for most academic re-use).
- Open code. Share analytical scripts in a version-controlled repository (GitHub, GitLab) so the analysis can be re-run end-to-end.
- FAIR principles. Findable, Accessible, Interoperable, Reusable: the operational standard for research-data stewardship.
Reporting standards: CONSORT, STROBE, COREQ, TRIPOD
Each study design has a documented reporting standard. Following the right one is what allows reviewers, readers, and synthesisers to judge the work and reuse it. The Equator Network catalogues hundreds of standards and is the canonical place to find the one that fits your design.
- CONSORT 2010[4] for randomised controlled trials. 25 items plus a flow diagram covering trial design, randomisation, blinding, outcomes, and analysis.
- STROBE 2007[5] for observational studies (cohort, case-control, cross-sectional). 22 items covering design, setting, participants, variables, bias, and statistical methods.
- COREQ 2007[6] for qualitative research using interviews and focus groups. 32 items across the research team, study design, analysis, and findings.
- TRIPOD 2015[7] for diagnostic or prognostic prediction-model studies. 22 items covering development, validation, and reporting of model performance.
- PRISMA 2020 for systematic reviews and meta-analyses (see the PRISMA 2020 guide).
Critical appraisal
Critical appraisal is the structured judgement of a study's methodological quality. It is what reviewers and supervisors do when they read a paper, and what authors should do to their own work before submission.
The Critical Appraisal Skills Programme (CASP) publishes free, design-specific checklists (RCT, cohort, case-control, qualitative, systematic review, diagnostic, economic) that walk a reader through the questions to ask. For risk-of-bias appraisal in systematic reviews, RoB 2.0 (randomised studies) and ROBINS-I (non-randomised) from the Cochrane Handbook[8] are the standards.
Whichever framework you use, the discipline is to make appraisal explicit and recorded, with two reviewers and a third for arbitration where the design warrants. An appraisal that lives in one researcher's head is, for practical purposes, no appraisal at all.
Common methodological pitfalls
The same handful of methodological errors appear across disciplines. Avoiding them is the easiest credibility win available to a researcher.
- Underpowered design. Sample-size calculation skipped or fudged at the protocol stage. The study cannot reliably detect even a real effect, and a null result is uninterpretable.
- p-hacking. Running multiple analyses (subgroups, alternative outcomes, alternative models) until something crosses p < 0.05, then reporting only that one. Pre-registration is the prophylactic.
- HARKing. Hypothesising After the Results are Known. Re-writing the introduction so the post-hoc finding looks like the planned one. Pre-registration prevents this too.
- No pre-registration. Without a public, time-stamped protocol, readers cannot tell confirmatory analyses from exploratory ones.
- Vague reporting. Missing inclusion criteria, undocumented exclusions, opaque analytical decisions, or statements like "we performed standard analyses" with no specification. The relevant reporting standard exists for a reason; follow it.
AI-assisted research methods
AI assistance is now a credible part of the methods toolbox, but only for the parts of the lifecycle where its strengths apply. Used well, it compresses the mechanical work; used poorly, it produces faster versions of the same methodological errors.
- Where AI helps. Literature mapping and feasibility analysis at protocol stage; multi-database searching with deduplication; first-pass screening at scale (with human verification on borderline calls); structured data extraction with dual-AI cross-verification; statistical-test surfacing from plain-English questions; PRISMA 2020 flow-diagram and checklist generation.
- Where AI does not help. Framing the research question; exercising ethical judgement; deciding whether a study design is appropriate; interpreting an unexpected result; deciding whether evidence is sufficient to change practice. These remain human work.
- What integrity requires. Dual verification (AI + human, or AI + AI with human arbitration), full audit trails of every AI decision, transparent reporting of which steps were AI-assisted in the methods section, and zero-data-retention guarantees from the platform.
The PRISMA 2020 statement explicitly added an item for reporting automation tools used in the review process. Equivalent transparency is appropriate in primary research where AI assistance touched the methods.
Frequently asked questions
Do I need ethics approval for a literature review or systematic review?
Most institutions consider systematic reviews of already-published literature exempt from formal ethics review because they do not involve new human-participant data. Always check your institution's policy: some require a brief notification or expedited review, particularly when individual-participant-data (IPD) meta-analysis is planned. Primary research involving human participants, their data, or biological samples always requires full ethics approval.
How do I calculate sample size?
Sample size depends on effect size, desired power (typically 0.80), significance level (usually 0.05), and the statistical test you intend to run. Cohen's seminal text remains the standard reference for power calculations across the major test families. Tools such as G*Power, the R `pwr` package, and PASS implement these calculations. Pre-specify the sample size in the protocol before data collection begins, not after.
Should I use a parametric or non-parametric test?
Use a parametric test (t-test, ANOVA, linear regression, Pearson correlation) when the data are continuous, approximately normally distributed, and the sample is reasonably large. Use a non-parametric alternative (Mann-Whitney, Kruskal-Wallis, Spearman correlation) for ordinal data, small samples, or skewed distributions. Always check assumptions explicitly rather than defaulting to parametric methods because they are familiar.
What is the difference between pre-registration and a registered report?
Pre-registration is a public, time-stamped record of the protocol (typically on OSF, AsPredicted, or PROSPERO for systematic reviews) made before data collection or analysis begins. A registered report goes further: the protocol is peer-reviewed and provisionally accepted by a journal before the study is conducted, with publication contingent on adherence to the protocol rather than on the results.
Do I need to comply with GDPR if I am not based in the EU?
GDPR applies to any research collecting, processing, or storing data on EU residents, regardless of where the researcher is based. HIPAA applies to US protected health information. The Australian Privacy Principles (APPs) cover personal information held by Australian organisations. If your research crosses jurisdictions, you may need to satisfy multiple frameworks, and the strictest of them in practice sets the floor.
What is the right reporting standard for my study design?
Use CONSORT for randomised controlled trials, STROBE for observational studies (cohort, case-control, cross-sectional), COREQ for qualitative research, TRIPOD for prediction-model studies, and PRISMA 2020 for systematic reviews and meta-analyses. The Equator Network catalogues hundreds of reporting standards and is the canonical entry point for finding the one that fits your design.
If you are designing a study, planning the analysis, or preparing a manuscript, Systematicly can absorb the mechanical parts of the lifecycle while leaving every judgement call with you. Start a free project at research.systematicly.com to try it on your protocol or your data.
Summary
Research methods cover the full lifecycle of an investigation: question, design, sample, ethics, conduct, analysis, and reporting. Each step has documented best practice (Declaration of Helsinki and ICH-GCP for ethics, Cohen for power, CONSORT and STROBE and COREQ and TRIPOD and PRISMA for reporting, the Cochrane Handbook for evidence synthesis), and the discipline is in following it. AI assistance helps with the mechanical work; the judgement calls remain human. Systematicly automates the analytical and reporting steps with audit trails throughout, so the methods section of the final manuscript reflects the work as it actually happened.
Ready to spend less time on methods overhead?
Systematicly handles the analytical and reporting steps of the research lifecycle with feasibility analysis, plain-English statistical-test selection, dual-AI extraction, and full audit trails. See your first analysis in minutes.
References
- Cohen J. Statistical Power Analysis for the Behavioral Sciences. 2nd ed. Lawrence Erlbaum Associates. 1988. ↑
- World Medical Association. WMA Declaration of Helsinki: Ethical Principles for Medical Research Involving Human Subjects. JAMA. 2013;310(20):2191-2194. ↑
- International Council for Harmonisation. ICH Harmonised Guideline: Integrated Addendum to ICH E6(R1): Guideline for Good Clinical Practice E6(R2). ICH. 2016. ↑
- Schulz KF, Altman DG, Moher D, for the CONSORT Group. CONSORT 2010 Statement: updated guidelines for reporting parallel group randomised trials. BMJ. 2010;340:c332. ↑
- von Elm E, Altman DG, Egger M, et al. The Strengthening the Reporting of Observational Studies in Epidemiology (STROBE) statement: guidelines for reporting observational studies. Lancet. 2007;370(9596):1453-1457. ↑
- Tong A, Sainsbury P, Craig J. Consolidated criteria for reporting qualitative research (COREQ): a 32-item checklist for interviews and focus groups. International Journal for Quality in Health Care. 2007;19(6):349-357. ↑
- Collins GS, Reitsma JB, Altman DG, Moons KGM. Transparent Reporting of a multivariable prediction model for Individual Prognosis Or Diagnosis (TRIPOD): The TRIPOD Statement. BMC Medicine. 2015;13:1. ↑
- Higgins JPT, Thomas J, Chandler J, Cumpston M, Li T, Page MJ, Welch VA (editors). Cochrane Handbook for Systematic Reviews of Interventions. Version 6.4. Cochrane. 2023. ↑